九、Elasticsearch 教程: 中文分词 – 结巴分词
上一章节中我们牛刀小试了一下 Elasticsearch,使用 Elasticsearch 的标准分词器对我们的英文问候语进行了分词,但是,这个分词器对中文的分词结果却不尽人意
你也知道,我们中文没有所谓的空格分隔的词,只有黏在一起的字组成的词
于是,我们必须装一个中文分词插件
百度或Google 一下 Elasticsearch 中文分词 ,你会发现大量的文章和大量的分词器
但这里,我们只使用 结巴分词
结巴分词
结巴分词 是一个简单的相当流行的 Python 中文分词组件
它有以下特点
1、 支持三种分词模式:;
1、 精确模式,试图将句子最精确地切开,适合文本分析;
2、 全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;
3、 搜索引擎模式,在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词;
2、 支持繁体分词;
3、 支持自定义词典;
4、 MIT授权协议;
虽然它的官方版本使用 Python 语言开发
但很多热心的开发者把它翻译成了各种语言,其中 Github 上的 Cheng Zhang 用户就制作了一个 Elasticsearch 版本的结巴分词插件
Elasticsearch 结巴分词插件
Elasticsearch 结巴分词插件的官方地址为 https://github.com/sing1ee/elasticsearch-jieba-plugin
你可以在简介中看到各个版本的结巴分词插件
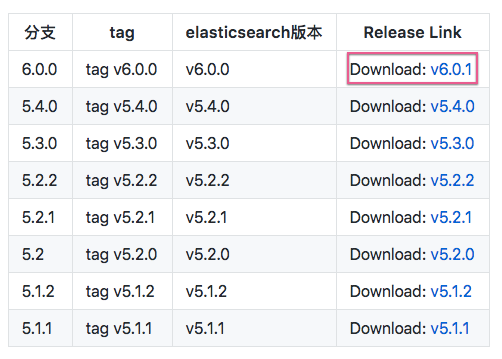
因为我们使用的是 6.3.0 的版本,所以我们选择下载 v6.0.1
安装
下载完成后��先不着急解压,正如官方文档所言,需要使用 gradle 工具来生成 jar 文件